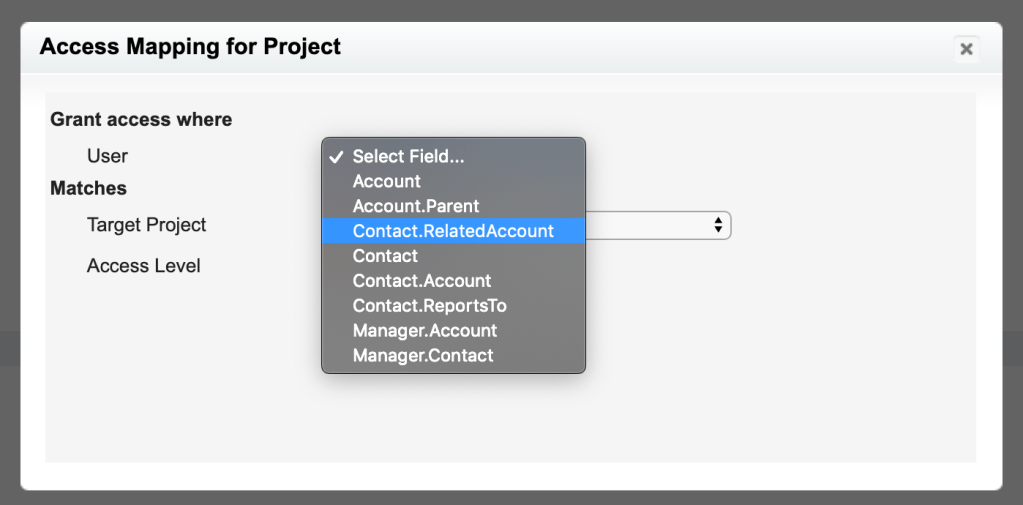
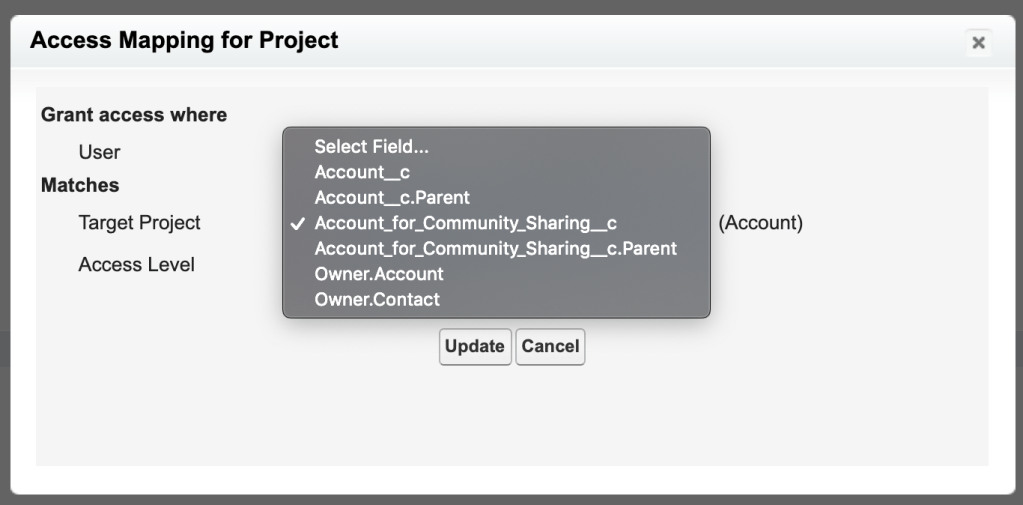
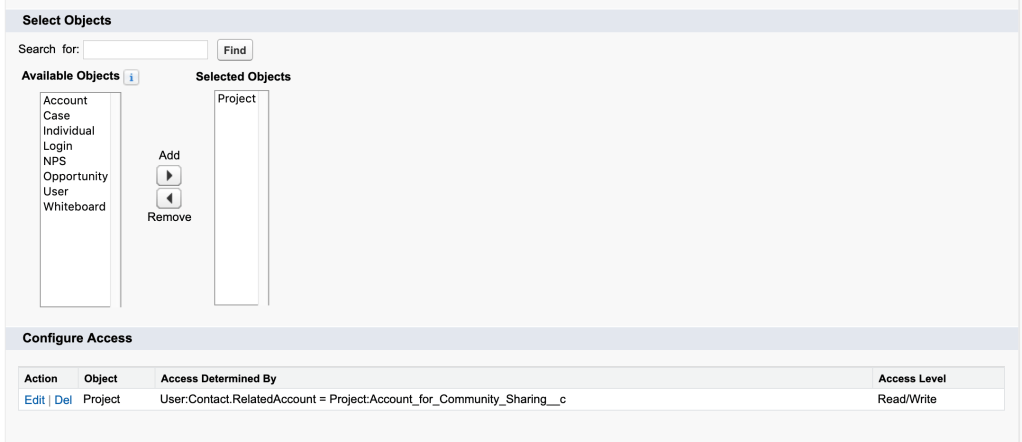
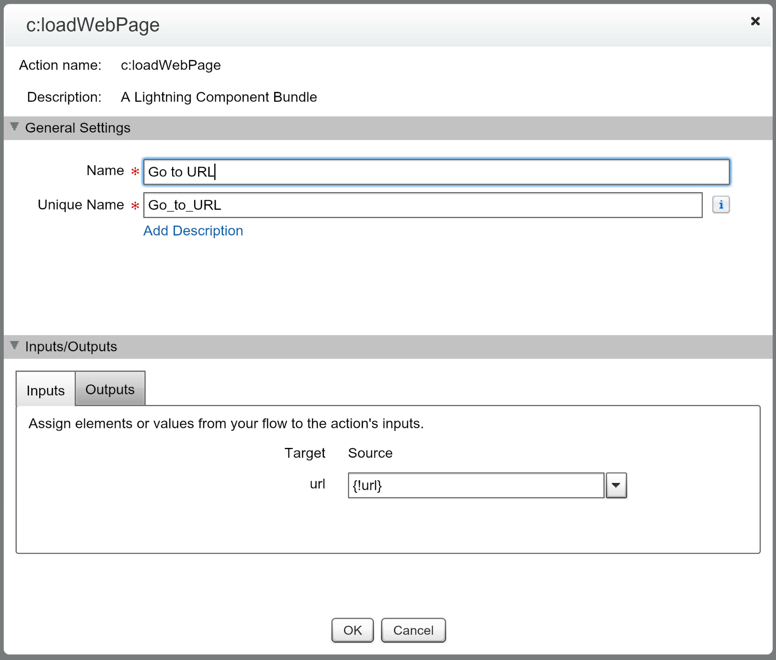
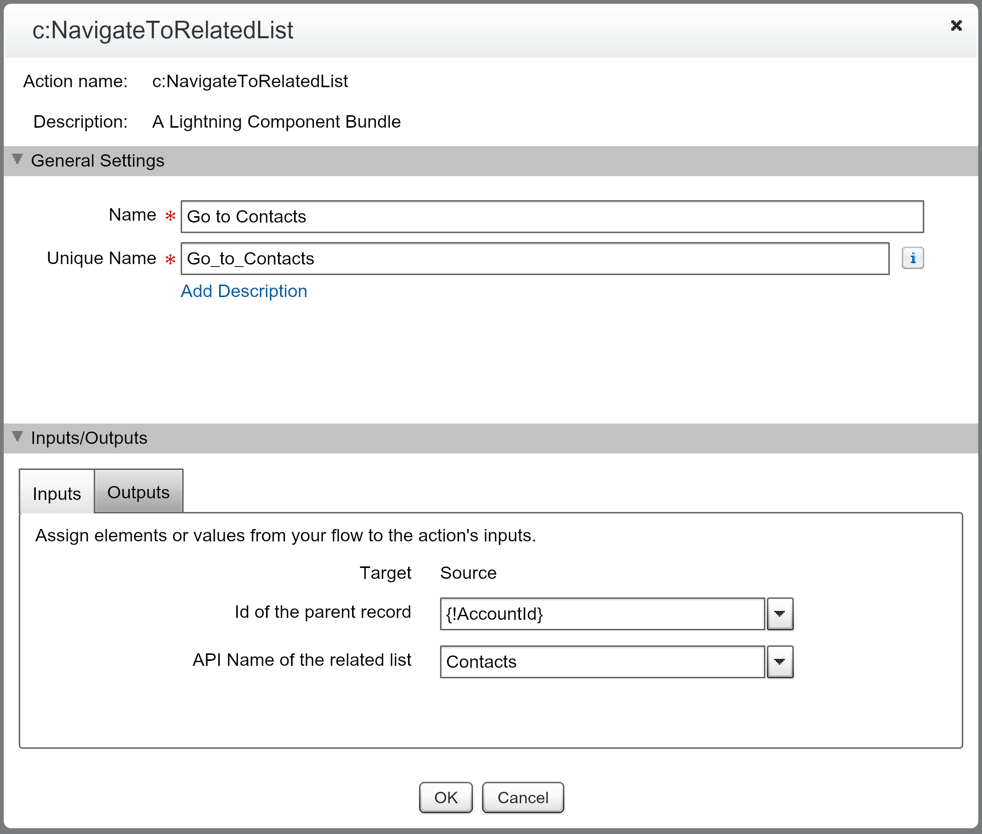
These Best Practices will help you look polished when presenting to Clients or Co-workers. These tips don’t really require any skill, they just require being prepared and aware when you’re about to share your screen. The underlining theme of this post is to minimize the distractions that can cause your audience to not focus on what you want them to focus on. By following these best practices (if you didn’t already), hopefully you’ll be able to provide a better screen share experience for your audience.
I use a Mac, so some of these will be tailored towards Mac Users.
Enable Do Not Disturb
There are countless reasons why you want to always use Do Not Disturb when presenting. Your Client/Coworkers do not need to see messages from your family and friends popping onto the screen. Also, if there is a group chat (ex: Google Hangouts, Slack, or Discord), you don’t have any control over what might be talked about while you are sharing or after you had started sharing.
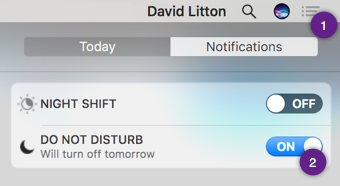
Michael Welburn recommended using Muzzle App. Muzzle App will silence your notifications automatically when you’re screen sharing. This takes the chance of you forgetting to engage DND before you are sharing.
Use the Full Screen
Having your application window not take up the whole screen is painful. How do my eyes not wander around the rest of your screen looking at your Folders or other visible Applications?
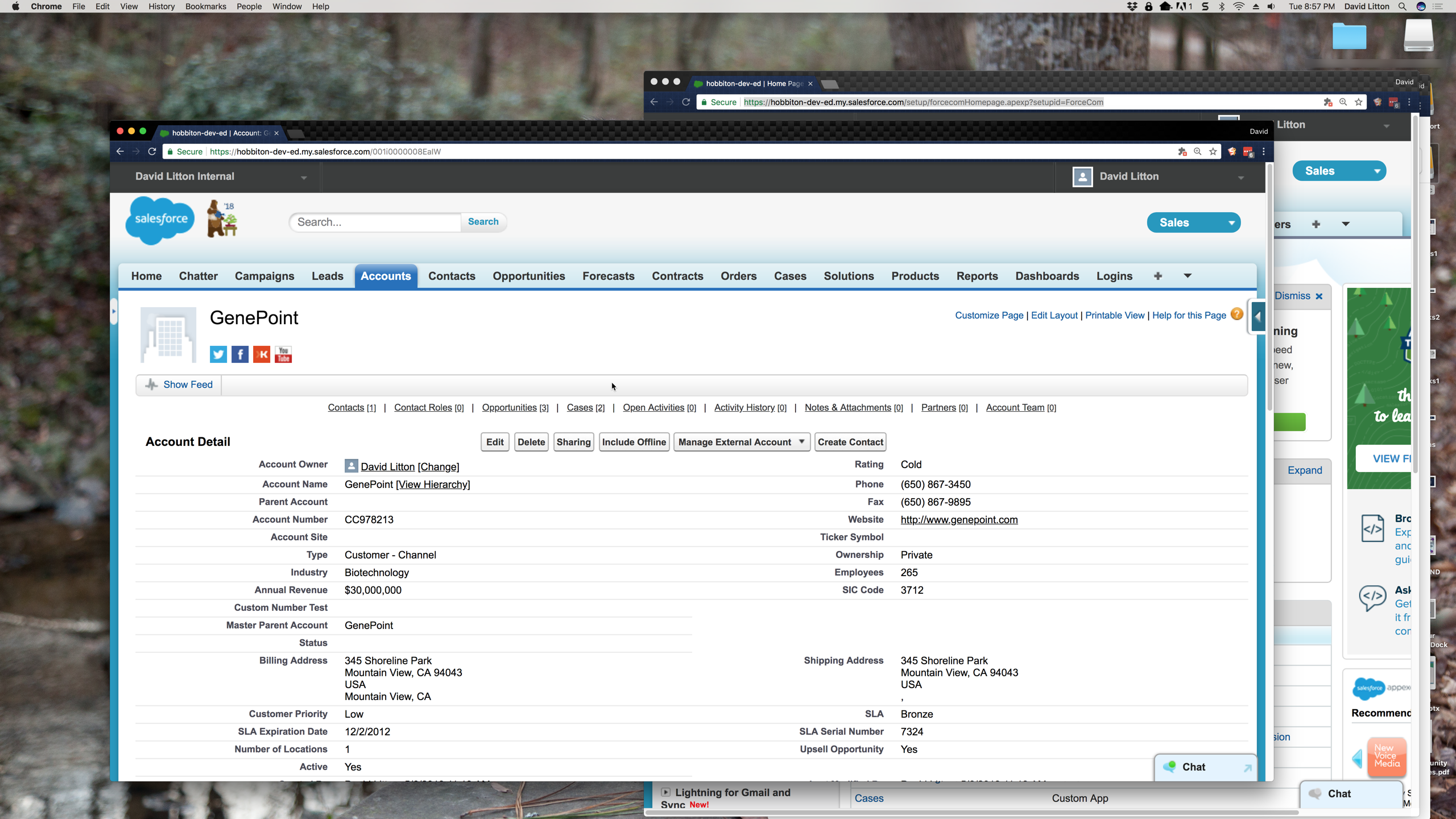
Hide your Dock
Even in the below screen shot where the Dock is small, it’s adding taking the focus off what I’m presenting on. In addition, why does the person watching my screen need to see what Applications I have open. With the Dock always showing, your Applications are unable to take up your whole screen, as they’ll stop at the top of your Dock. You can still access your Dock briefly, but because it will hide itself after being used it won’t be a big distraction. Keep an eye on what you keep in your Dock, it’s just like your Bookmark Bar and Chrome Extension (to be talked about soon).
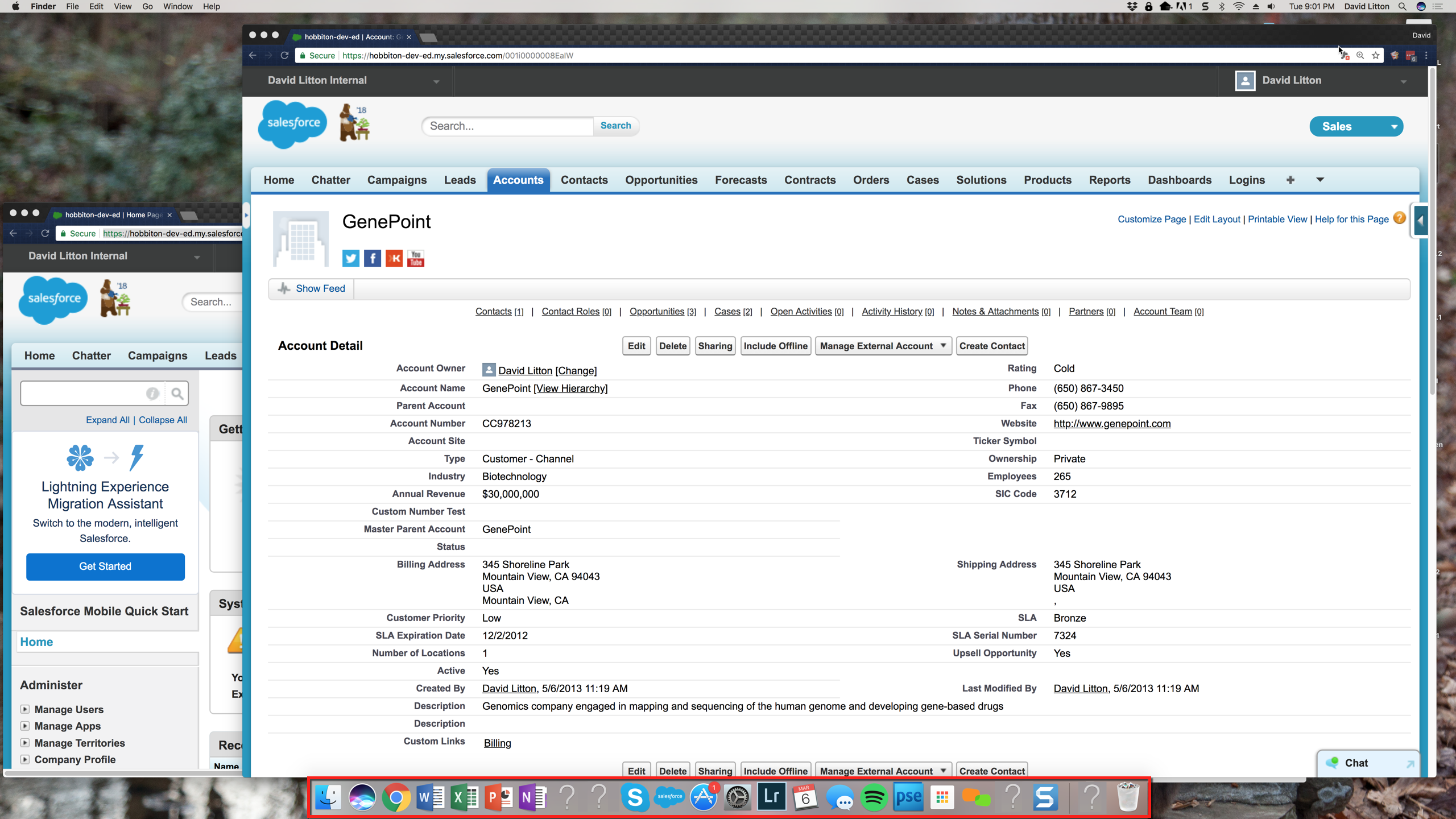
Don’t have unrelated Tabs visible
This one I used to be guilty of. I would share my screen with 50 Tabs open. Split out the Tabs that you need to use for your presentation, and hide or close the others. Pay attention to what Tabs you do choose to keep open. I’ve seen many questionable Tabs left open when someone shares their screen. Tabs give a short summary of what you’re looking at, so don’t think people can’t tell. Any non-related Tabs being visible really don’t help.
Avoid Email, Texts, and Chats
This is similar to the Do Not Disturb point, but it has to be said. Nobody whose watching you demo Salesforce needs to see your Inbox or Chat screen. If you must navigate to your Inbox or Chat, pause the Screen Share. You have no idea what Emails might just have been sent to you, or messages your Team or other groups have sent. There is no good that comes from showing Email or Chat on a screen share.
Whether you have 20,000 or 2 emails in your Inbox, don’t be showing it off.
Hide Bookmarks Bar
It was strange at first when I hide my Bookmarks Bar. But, opening a new Tab or using the Bookmarks
Don’t keep this Docked for your presentation. It takes up a decent amount of screen space, and the people watching your screen will be distracted from your presentation and read your Bookmarks.

You can access through the top bar.
Cleanup those Extensions
While you can technically access all of your extensions without having them visible, there are going to be some that you simply use too often to not have visible. That’s fine. Just work to keep this to a minimum. You don’t want to have half of your address bar taken up by extensions.
Before

After

Does that remind you of a show on HGTV? It’s amazing how much cleaner the Browser looks. You’re not taking the viewer’s eye off of your presentation anymore. And, you can still access less frequently used extensions quickly.

Use the Presentation Mode
If you’re doing something that has lots of distractions, like Lucid Chart, use the Presentation Mode. Even if your browser is using the Full Screen, it’s going to be hard for your audience to Focus with all of the awesome shapes they have available.

Zoom to a reasonable level
This one I am guilty of forgetting about the most. Be mindful of the size of your screen and your audience. I tend to work zoomed out Salesforce, and have to zoom in when I am sharing my screen. It’s extremely easy to do this, and if you’re unsure you can always ask your audience if they can see your screen clearly.

Use multiple monitors
Using multiple monitors allows you to “cheat” and possibly have search Google, have Setup Menu of the Org open, take Notes, and communicate out sight of your audience. The biggest trick here, is making sure you know which Monitor is being shared. In some cases, you might be in a new screen share program and not sure what the defaults are. Make sure both monitors don’t have anything listed in this post visible when you accept presentation, once you are sure the right monitor is being shared you can open other applications.
One of my favorite tricks with my second Monitor is to login to the Org(s) I am working in on my second monitor. This allows me to drag in the prepared window into my other screen and the viewers do not see any of the Login process. I find this very important if you’re a Consultant, because you don’t want your other Clients names visible through the saved Usernames that might be showing. Also, the viewers do not have to see you navigate through multiple pages. You look more prepared.
Mission Control & Hot Corners
Mission Control is something that saves me an awful lot of trouble. I can easily see all my applications and select the correct one to go to. While, keeping all my applications full screen!
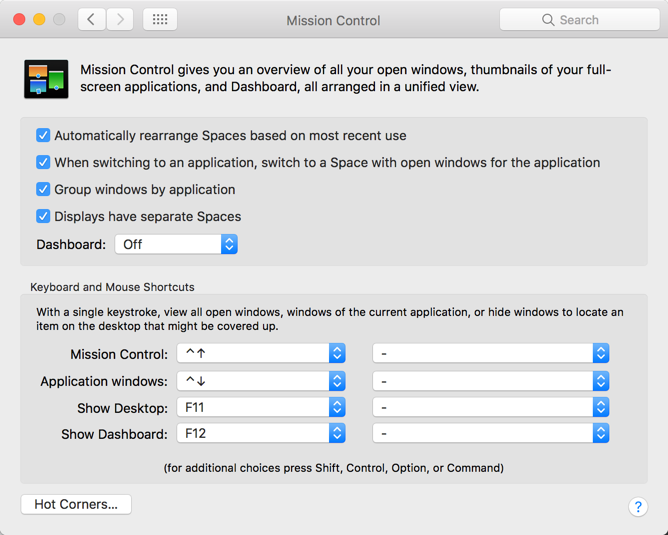
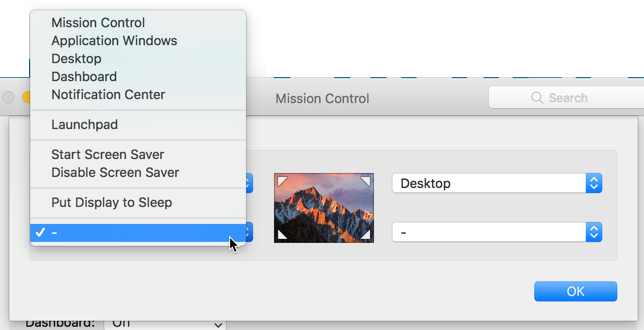
I personally love to use Hot Corners, and use that in most scenarios. The Hot Corners allow you to select one of the actions and have it happen when you move your mouse to that corner.
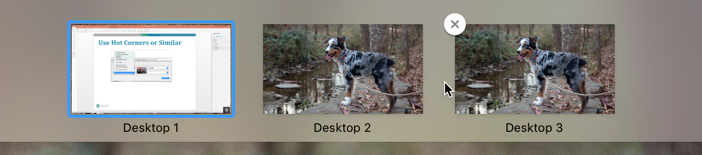
Mission Control also can help you utilize the Multiple Desktop feature. I don’t use it very often, but it does come in handy. And, if you’re unable to use two monitors, this could come in handy. It allows you to group your applications onto different Desktops.
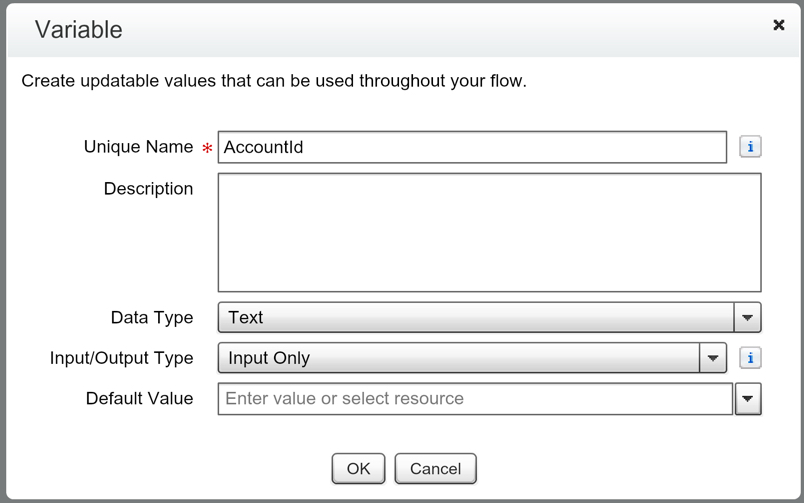
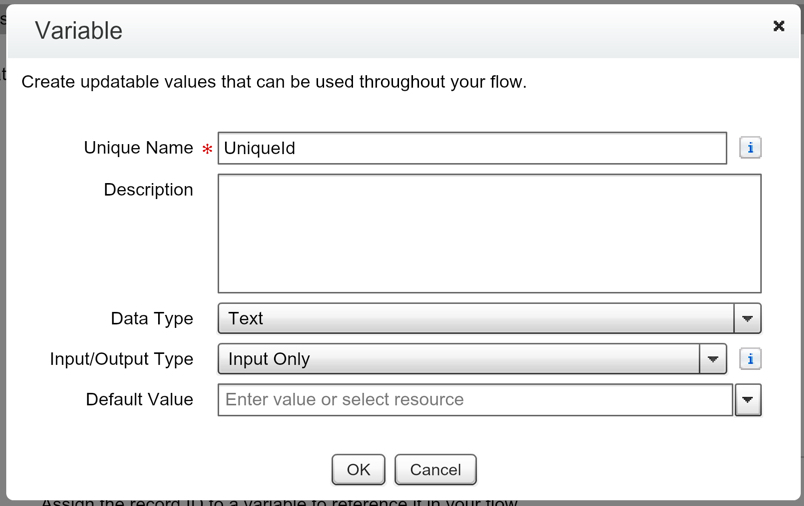
What’s your Road Map?
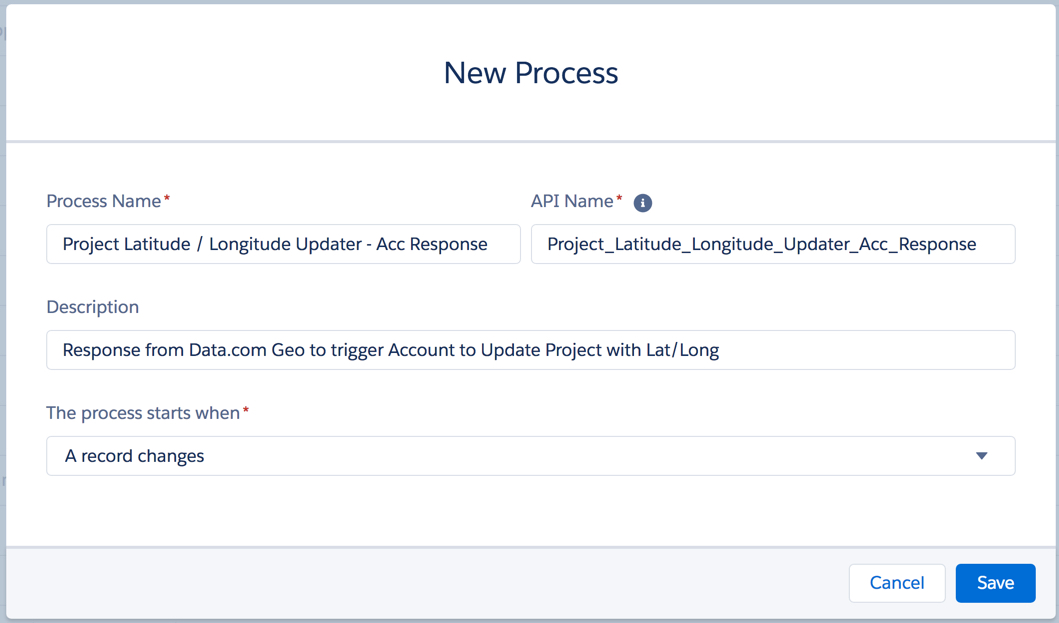
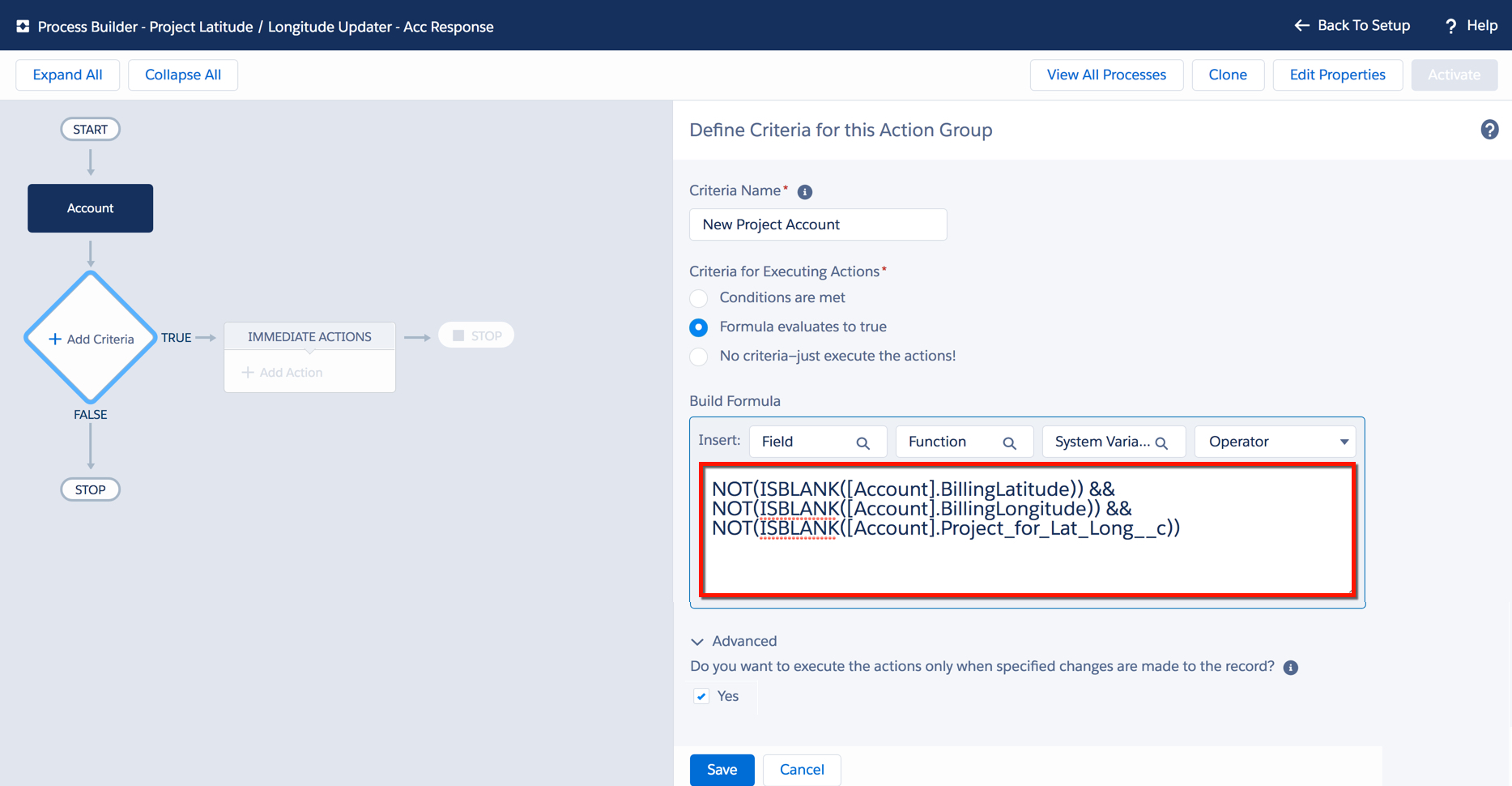
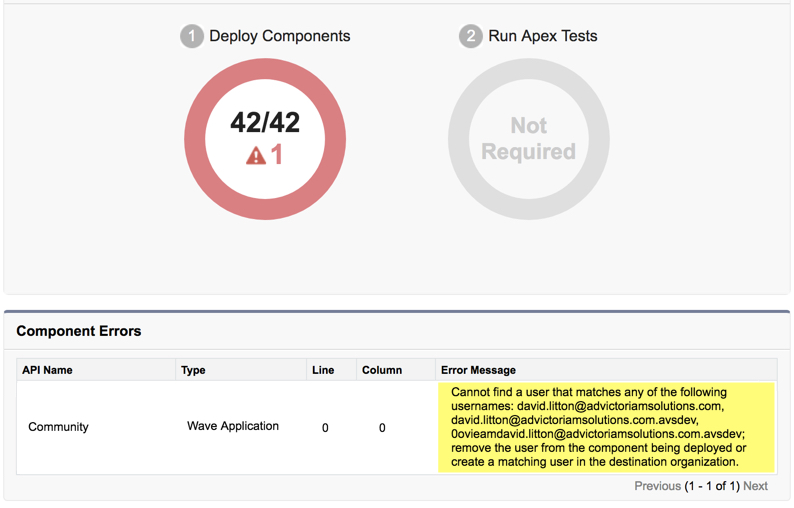
What are you demonstrating on your screen share? If you’re showing off a new piece of functionality that you built to a stakeholder, be prepared to with a good story. If you’re not able to make your presentation follow a storyline, it can seem disjointed and take away from the awesomeness that you built. You should do a dry run of your presentation, because running into an error (ex: Unhandled Fault) on a demonstration with a Client is not what you want to have happen. And, it could throw you out of rhythm and derail the rest of your presentation.
You Don’t Have to Share
Did someone just ask you to present and you aren’t ready? Or, did you get an email that you have to open, but you only have one monitor? Don’t be afraid to pause/stop the screen share until you’re ready. Tell your audience to hold on for one moment, and resume (or begin) the screen share when you are prepared. Less can go wrong when you are not sharing your screen, than trying to fumble around while your screen is being shared.